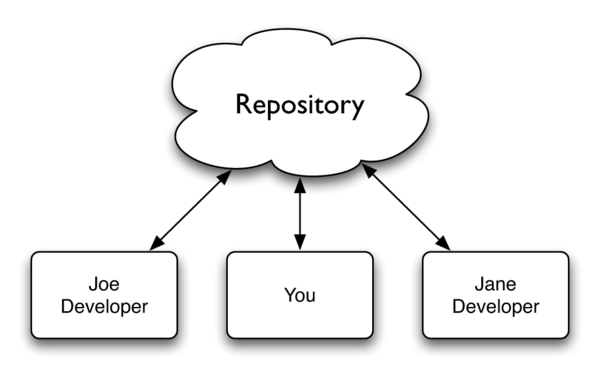
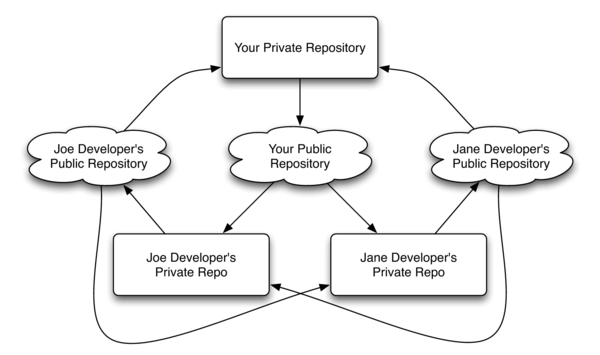
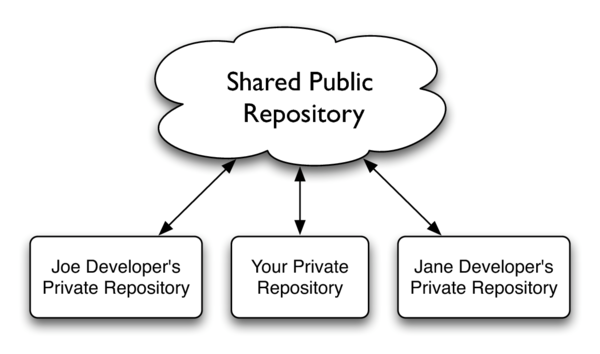
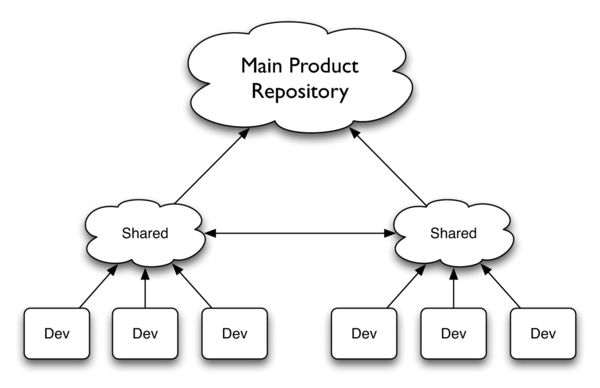
The following is an extract from the Pragmatic Bookshelf title Pragmatic Version Control Using Git by
This extract is formatted in HTML, and so has a different layout to the book itself. To some extent this layout depends on how your browser is set up. Note that this extract may contain color—the printed book will be grayscale.
Visit the book's home page to purchase this title.